
Balancing Act
This article covers the concepts around de-duplicating contacts. If you want to jump to the chase and learn how to run the de-dupe process, please see our screen cast on de-duping.
Every organizing strategy has to manage a balancing act when it comes to entering contacts into your database:
- On the one hand, we don't want to create duplicates. If we are importing a record for Alberto, and Alberto is already in the database, we want to update his record, not create a duplicate.
- On the other hand, we don't want to update the wrong record. What if the new Alberto we are bringing into the database is different from the one in our database? If we update our existing record, it will create a big mess.
This balancing act has to be re-enacted in many very different situations. For example:
- When importing a spread sheet
- When a staff person enters a record by hand
- When a person makes a contribution via a public contribution page
- When a person registers for an event
- When someone fills out a profile online or fills out a webform
Dedupe rules
CiviCRM decides whether to create a duplicate or merge with an existing contact based on a set of de-dupe rules.
A de-dupe rule essentially says: Every time a new contact is about to be entered, see if there are any existing contacts in which the following fields are the same. If there is an existing contact, then update that contact rather than creating a new one (if there is more than one matching contact, the first one found is updated).
As you can imagine "the following fields" is the critical part.
Some organizers rely exclusively on email address matching rules. If the email address is the same, then we declare it to be the same.
Other situations require more nuance. For example, what if someone registers several people to an event but doesn't know all of their email addresses? They might enter their own email address for all of them.
Some organizers require that the first name, last name and one of the following match: email, phone or street address.
Your dedupe rules page
The best place to start thinking about de-duplication and merging is with your de-dupe rules page. Here's a screen cast on how to work with Dedupe Rules
This page lists the rules that CiviCRM follows when determining if two contacts are the same person or not.
You can access it via: Contacts -> Find and Merge duplicate contacts
The default settings look like this:
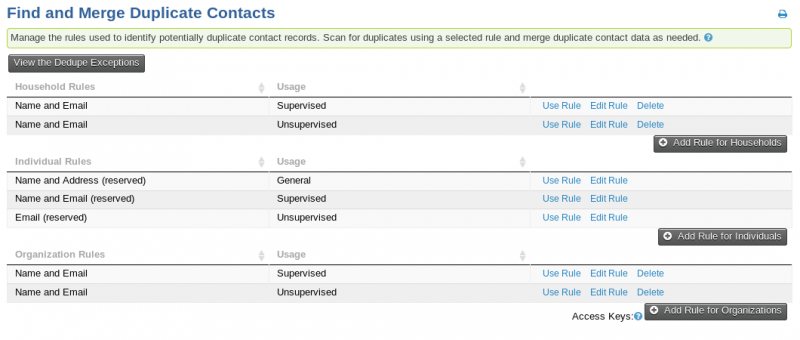
Since we don't use Households, you can ignore those rules.
That leaves rules for handling organizations and rules for handling individuals.
Let's focus on individuals.
You can create as many rules as you want, but you always must have at least one "Unsupervised" rule and at least one "Supervised" rule.
The "Supervised" rule is used by default anytime a contact is added by someone who is logged in and paying attention. In other words, when you manually add a contact.
The "Unsupervised" rule is used all other times. For example: when a user registers for an event or makes a contribution or fills out a profile. In addition (and this is a bit unintuitive), it is also used during imports. While there is a logged in user who is paying attention, they are not able to review every single one of the imported contacts. As a result, the "Unsupervised" rule is used.
What a dedupe rule looks like
If you click to edit a dedupe rule, you can see how it works.
If you pick one that is "reserved" (meaning you can't change the rule), it might look like this:
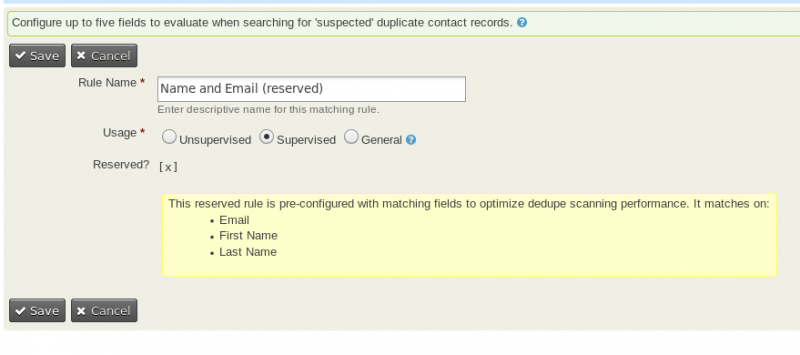
This rule is pre-configured to trigger if the first name, last name and email address all match.
This screen also shows you how to change a rule's settings from General to Supervised or Unsupervised.
Additionally, you can create your own rules, but that is best left for later.
How do I use these rules?
At any time, you can use these rules to find duplicate records in your database and merge them. That process is covered in our Dedupe screencast.
However, there are many other ways to use these rules.
Importing
When importing contacts, you can choose what to do with duplicate records.
But there's more... you can also choose which dedupe rule you want to use for every individual import.

For example, your default unsupervised rule might be to match on email address only. That could work for most imports. But one day you might import records that don't have an email address. For that import, you may need to use an import rule that matches on name and street address.
Profiles
If you are collecting data via profiles, you can click the Settings link, then expand the Advanced accordion and modify what action to take if a duplicate is found (note: profiles always use the Unsupervised rule):

This setting only applies to stand-alone forms. If a profile is part of a contribution or event registration form, then the contribution/registration information will always be added to the matched contact (if one is found).
Events
With online event registration pages, you can specify which dedupe rule should be used. By default, the unsupervised rule will be chosen, but you can change it:
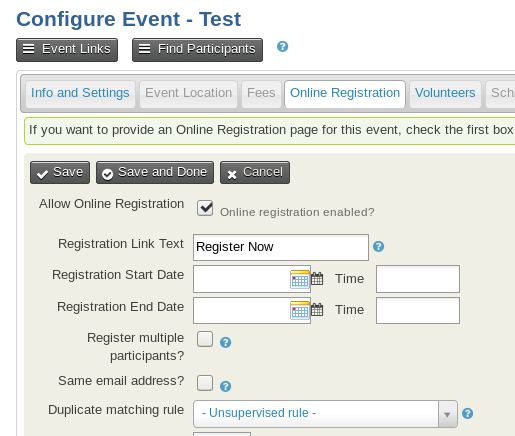
For example, if you always want duplicates created for event registration, you could specify an impossible to match de-dupe rule for a particular event.
How to create your own dedupe rule
Now that you have the big picture, you may want to create some custom de-dupe rules. Here's a screen cast on how to work with Dedupe Rules
You can do that by going to Contact -> Find and merge duplicates and clicking the button to add a new rule.
Here's an example rule that can be useful:
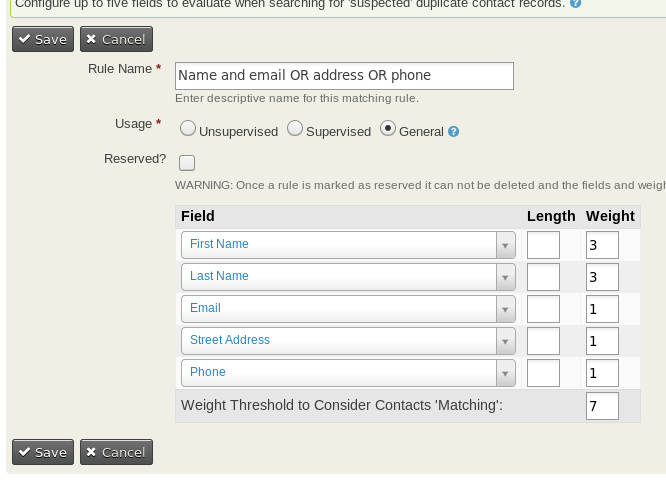
You can select any field you want from the field drop down.
The length column allows you to specify the length of the field you want to search. For example, if you chose First Name and length 3, then it would only match the first 3 characters of the first name, so "Jamie" and "James" would be considered a match. Despite the usefulness of this feature we discourage it's use because it causes your database queries to slow to a crawl and often timeout..
The weight column describes what score a match should get.
Lastly, the Threshhold column determines what total score should decide if it's a duplicate or not.
In the example above, if the first name, last name and email address match, the score would be 3 + 3 + 1, or 7. Since that matches the threshhold it would be considered a duplicate. If the email, phone and street address matched, it would only add up to 3, not enough for the score to match.
So, what should my strategy be?
If in doubt, set your Unsupervised rule to be quite strict (like first name, last name and email address) and regularly search for and merge duplicate records. It's far better to have a database full of duplicates than to try to untangle records that were merged that should not have been merged.